
AICAS
Automatic Intelligent Conversation Analysis System
AICAS is a system that processes and analyzes human conversation and written text from a computational linguistics perspective. AICAS is unique in that it has been designed to analyze conversations of both adults and children. It is powered by machine learning models for assessing diverse linguistic metrics.
Three Ways to Use AICAS for Research :
-
Using the web application on http://aicas.herokuapp.com
-
This method is intended for those who use AICAS for different conversations. Upload audio or text files, and the system processes this input and produces the results.
-
Constraints: A audio file not more than 3 minutes in length. Doc or docx files not more than 10 MB in size. If you wish to exceed these thresholds, use the next method or Email for assistance.
-
-
Running the environment on your computer locally.
-
This method is intended for those who are familiar with programming, software development, and machine learning. Email to obtain access. You will be able to download the models and could run them on different datasets and different scenarios.
-
There are no constraints on time and space.
-
-
Sending your requirements to us for analyzing a conversation from a linguistics perspective.
-
The users who are interested to opt this method are welcomed to mail Yanghee Kim, Ph.D. describing the specifics as to what would be the prospective parameters intended for development in order to analyze a conversation. This method is intended for users/organizations who want to have conversational discourse analysis from multiple dimensions.
-
Users who submit the requirements will be able to negotiate the time frame for building models and the final build would be delivered based on the complexity of the requirement and the computational feasibility of integrating a solution within the environment.
-
System architecture :
AICAS Tools:
AICAS is composed of four tools.
Automatic Speech Recognition (ASR)
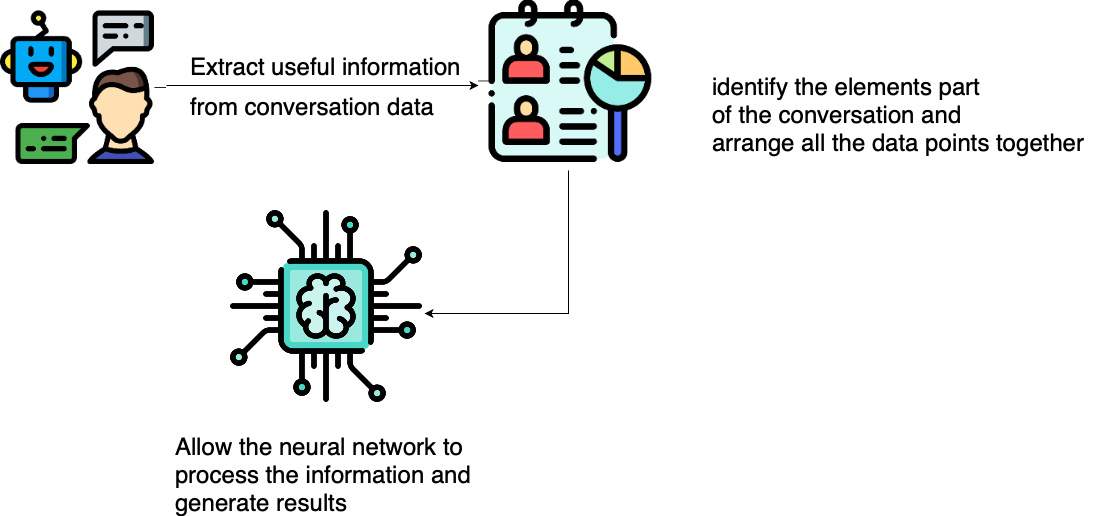
This tool recognizes conversations and transcribes them into text. Modern speech recognition systems have higher word error rate in detecting children’s speech data. However, our tool achieves minimum word error rate by employing state of the art automatic speech recognition software from Google, IBM and a personalized neural network that automatically transcribes children’s speech.

ASR tool functioning
Doc_Analysis
This tool analyzes conversation transcripts stored as MS Word documents. The system intelligently separates the speakers and their texts and assigns various linguistic metrics to the speakers. The metrics include lexical diversity, average word length, average sentence length, number of complex/difficult words (words greater than 2 syllables), polysemy, frequency of words greater than average word length, and syllable count. The tool will be expanded to support PDF’s in the future.
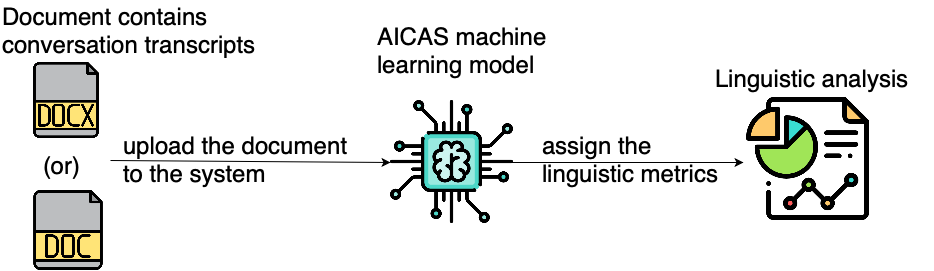
doc_analysis tool functioning
Co-occurrence Network
This tool essentially constructs networked graphs for analyzing the relationship of the words used in a conversation by two or more speakers. The graphs are weighted and have direction, so we can see how words as entities are being mapped to other words.
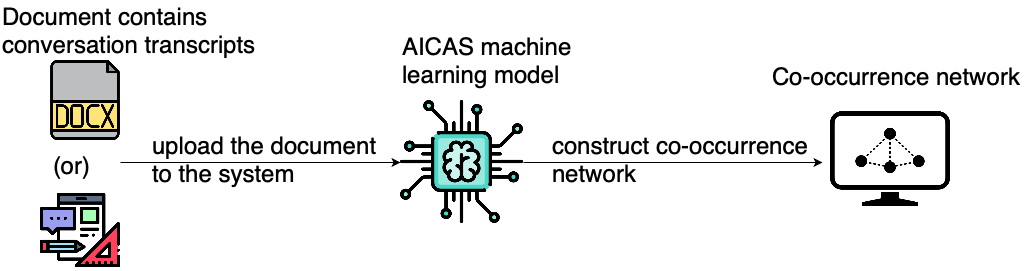
co-occcr_network tool functioning
Long/Short-term Memory-Based Semantic Similarity
This tool computes the semantic similarity of the transcribed speech of two or more speakers in order to see if their talks are semantically relevant. Distinct from other systems relying on the structure or syntax of the text, our tool focuses on the semantics of the text and helps determine if two speakers are talking about similar concepts.

lstm_semantic_similarity tool functioning